

Step up to the bizarro slot machine!
Token spend has come back to bite corporate America in a big way, now they're wondering if this carnival game is rigged.


When LLMs launched to the general public, part of that introduction was introducing the concept of tokens as a means of transacting with the models. At the time, the tokens themselves seemed innocuous enough; it was almost like the next generation of binary code to some, a method of machines understanding things that humans just needed to come to terms with.
As the business of AI matured, the concept of tokens, and more importantly the economy of tokens, remained fluid. For the record, tokens are phrases or bits of text that can be parsed by LLMs (Large Language Models) as part of their natural language processing; this, in turn, allows the LLM to function and make all the interesting connections it goes on to make.
That pricing has fluctuated as the cost of processing and building out the infrastructure of AI has ballooned up. Moreover, the way the tokens are used has changed quite a bit as well; what was once a simple back-and-forth transaction of prompt and response has been replaced by multi-agent, parallel-path, fully agentic workflows, churning through tokens the entire time.
Gizmodo just reported on a lawsuit where Anthropic reportedly misled users about tokens and token usage. Anthropic has been fiddling with their pricing model for a year or so now, and it’s drawn the ire of many a user, including myself. I’m a bit surprised to see them named in a suit like this, but token burn is real, and someone was going to feel it eventually.

Super Powered Approximation Machines
OpenClaw/Moltbot kicked off a fully agentic frenzy that calmed a bit but has not gone away entirely, likely because some form of the agentic workflows in these proto-builds gives us a glimpse of the future, which is why people got so excited by them. For those unfamiliar with OpenClaw, OpenClaw is an open-source framework for integrating a foundational LLM and sending off sub-agents to achieve tasks. This functionality has been essentially replicated by MCPs, though the automations still need some Python scripting and scaffolding to be executed.
What came from this was an obsession with agents and sub-agents: how to fully automate workflows into these machines that don’t need human intervention at all. People only asked if they could build something and stopped asking if they should. What happened was a lot of cognitive surrender to the agents, giving up logical decision-making to the machines and letting them spin until they came to a conclusion. Eventually, the agents would come back with an answer or something close, but only after spending a king’s ransom in tokens.
Frequently, I see Opus put forth in these fully agentic flows, which are totally hands-off. When I’m working with Claude Code, I’m working hands-on and document nearly every session to give Claude the best possible chance at success, and it still makes critical errors. One error just from today: it flat out told me I hadn’t deployed a function that has been deployed for over a month, but its memory had gone stale, so it was about to go on a completely destructive path. I had to stop it, remind it we actually had this function deployed, and send it the error code from the backend so we could get back on track, at which point we were able to resume work.
Using Anthropic’s own diagram’s I want to point out the issues with these workflows, the premise is logical but the conclusion is not. What these workflows assume is that AI has reasoning ability, it does not. AI has more of a funnel or probabilistic method of making decions, so instead of taking a linear course of action, it sort of winds it’s way to a solution.
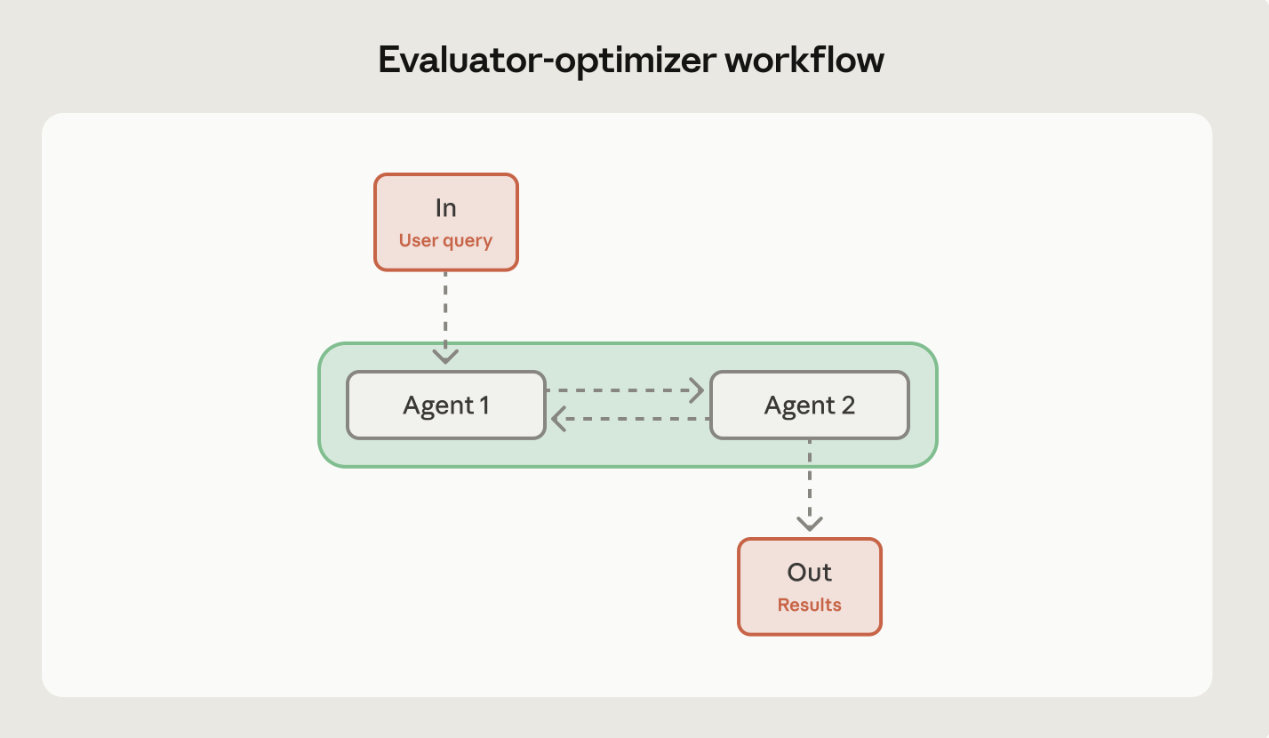
In this evaluator arrangement, the agents are assigned different roles. The example would be: Agent 1 writes the code, Agent 2 checks it against the PRD, and when the criteria are met, reports back to the human. This isn’t necessarily bad. My only issue is that what is being outsourced to Agent 2 could easily be avoided through clear documentation up front, spending time writing specs, and answering the agent’s questions as it goes. The user is missing out on opportunities to clarify issues like the one I flagged about the stale memory, as well as finding opportunities to improve the flows and learn from the AI as the process progresses.
One final note on this diagram: this loop can go on and on for several cycles before an output is reached. There’s no way to avoid token churn entirely, but in setups like this, there is always a risk of waste.
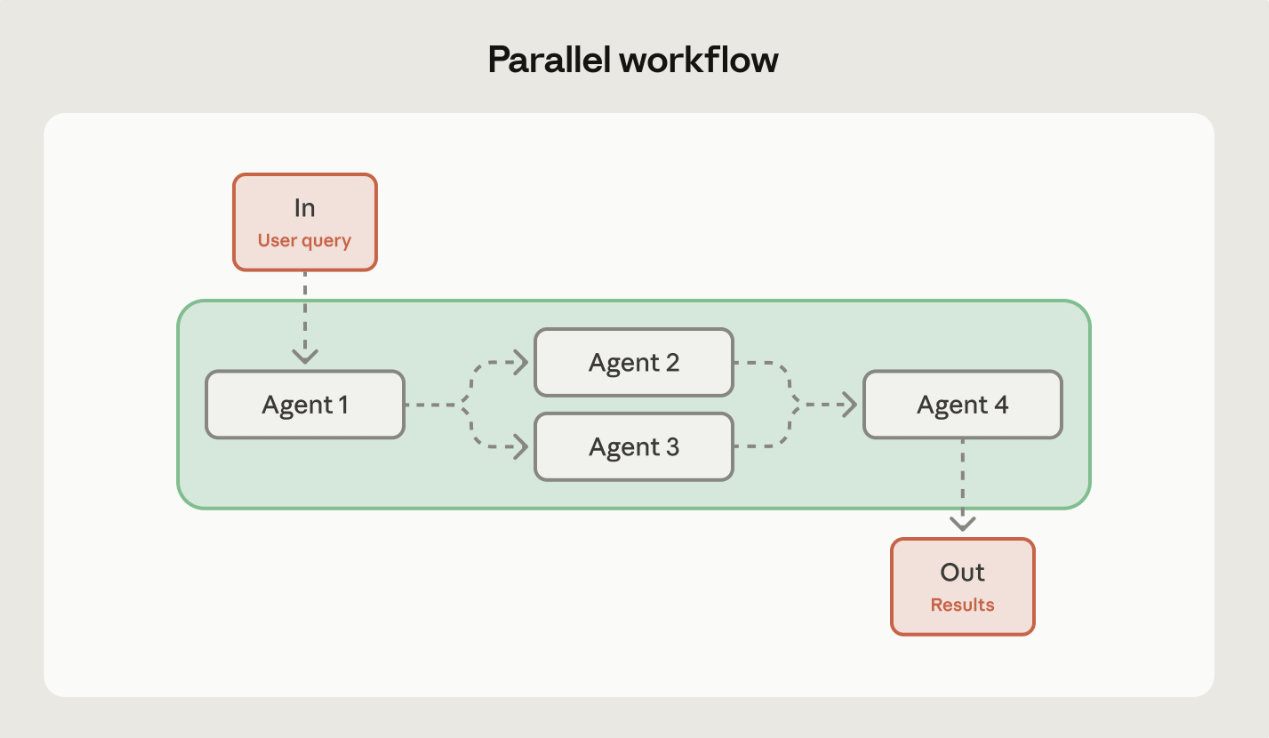
This next diagram is where things get spicy. This is where token churn is happening. This is where the AI, a machine with no reasoning ability, is being asked to make assumptions, draw conclusions, and extrapolate on whatever the user has input. As it uses its machine learning to connect the dots and plug the holes, it will eliminate possibilities and narrow in on what will eventually be the correct answer, or something like it. What’s interesting about this flow is that they aren’t showing the quality control of the evaluator phase, but I suppose it’s meant to be like assembling different components of a machine.
I saw a version of this diagram where the planning and the research were happening in parallel to each other, which is completely counterintuitive. How is it possible to plan without the research being complete? There seems to be this notion that AI can completely upend all logical constructs, even time-tested sequences, that somehow it’s become stateless and able to execute everything and anything all at once.
Suffice it to say, when I see workflows like this one below, I cringe. There is no code owner here; there is no domain knowledge. Beyond that, the orchestrator stage is burning a fortune trying to compensate for the cognitive offload the human deferred to it.
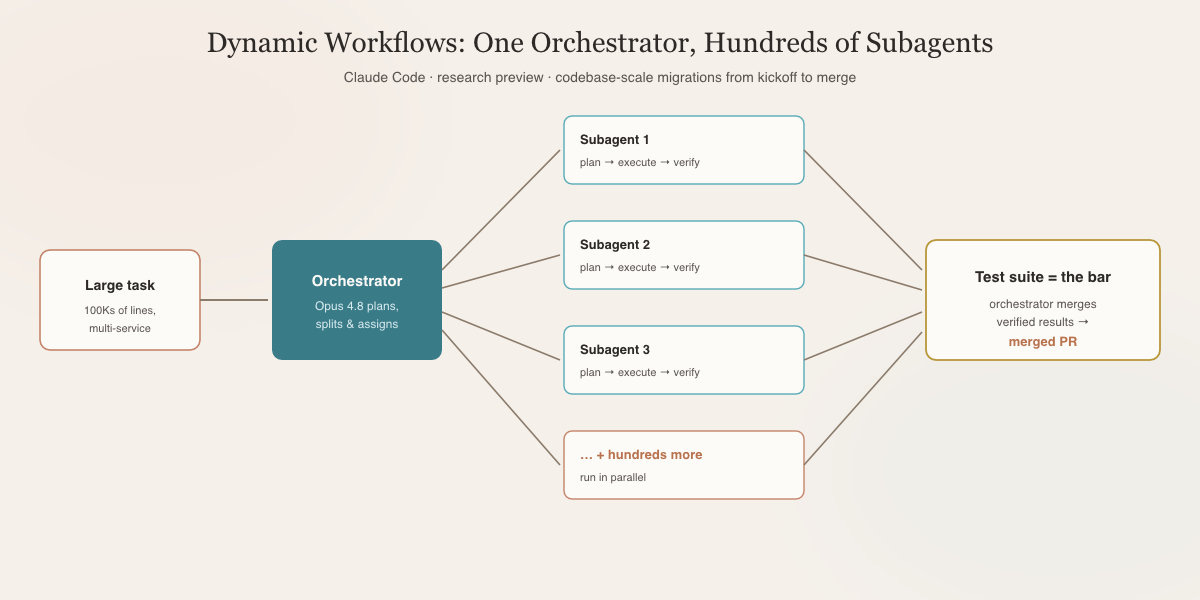
Artificial Intelligence is a misleading term. It gives the impression that we’ve created a little person inside a machine that’s making decisions; we have not. The best we’ve done is we have created an extremely good and expensive approximation machine. It will get you to the answer, but it will need to approximate along the way, and it will charge you the entire time, where a little planning and human intervention could save you a lot of time, effort, and tokens.
Tokenmaxxing is dead! Long live Tokenmaxxing!
Lest I get tokenmogged for this take, I’m glad tokenmaxxing is dead. Tokenmaxxing was dreamed up by Silicon Valley leaders as a way to track AI adoption and usage, but it was clearly thought up by someone who thought that tokens were free or something. At Meta, they had leaderboards to track token usage, which are now humorously out of commission.
If anything, though, it highlights how little leadership in these companies seems to understand AI, tokens, and the space at large. Like most things, though, it didn’t hit home until the bill arrived. That’s when we started seeing articles about companies budgetmaxxing on their agentic AI spend.
The core of tokenmaxxing, though, is leadership: well, 1. wanting to track their employees in a big-brothery way to see who’s adopting AI; 2. not knowing how to measure adoption of this technology any other way.
As disconcerting as the first point is, the second point is even more so. I think we’ve all been able to see some measurable improvement to some things thanks to AI, but with it we’ve also seen a lot of slop, slippage, and general malaise. AI blends in with regular work so well, and when done well, it fits seamlessly into existing workflows, so how do you even prove you’re using it?
The token economy as the new “cloud”
The branding of “The Cloud” was always a funny way of saying off-site servers, albeit an incredibly effective one. In a way, tokens are the same thing; they’re something very functional that has been abstracted and monetized. Time will tell if this truly is the correct way to value and price AI usage. As we’ve seen with tokenmaxxing, it hasn’t stood up to the test of HR and the workplace yet.
We do know that businesses and users are being charged in this way, though, and that could prove to actually limit the growth of the AI economy. If integrating with foundational LLMs is so expensive and onerous that it becomes a sizable part of a company’s burn, then it’s going to slow the growth of both companies: the foundational LLM provider and the startup.
In building my startup, I’ve chosen to remain LLM-agnostic and have chosen to host open-source options to control burn. As prices fluctuate and features are lobbed off, it’s impossible to build a business on the few leading foundational LLMs. I also think that more foundational models will be around the corner; there’s more disruption yet to come. I could be wrong on all of this, but it’s hard for me to believe this is the final, most perfect version of Large Language Models. At least, those are my two tokens.